网格搜索算法与K折交叉验证
网格搜索算法和K折交叉验证法是机器学习入门的时候遇到的重要的概念。
网格搜索算法是一种通过遍历给定的参数组合来优化模型表现的方法。
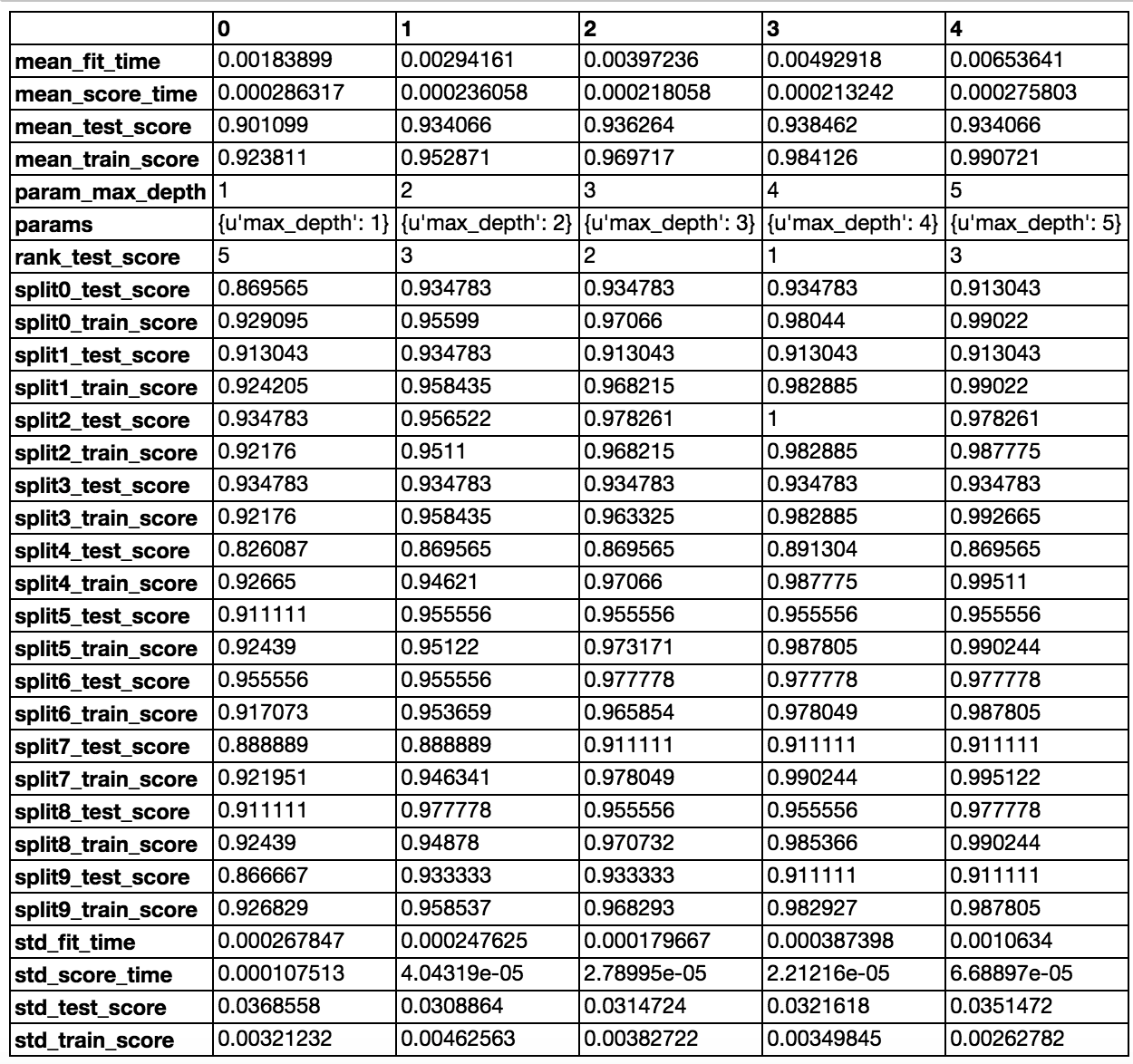
以决策树为例,当我们确定了要使用决策树算法的时候,为了能够更好地拟合和预测,我们需要调整它的参数。在决策树算法中,我们通常选择的参数是决策树的最大深度。
于是我们会给出一系列的最大深度的值,比如
{'max_depth': [1,2,3,4,5]},我们会尽可能包含最优最大深度。
不过,我们如何知道哪一个最大深度的模型是最好的呢?我们需要一种可靠的评分方法,对每个最大深度的决策树模型都进行评分,这其中非常经典的一种方法就是交叉验证,下面我们就以K折交叉验证为例,详细介绍它的算法过程。
首先我们先看一下数据集是如何分割的。我们拿到的原始数据集首先会按照一定的比例划分成训练集和测试集。比如下图,以8:2分割的数据集:
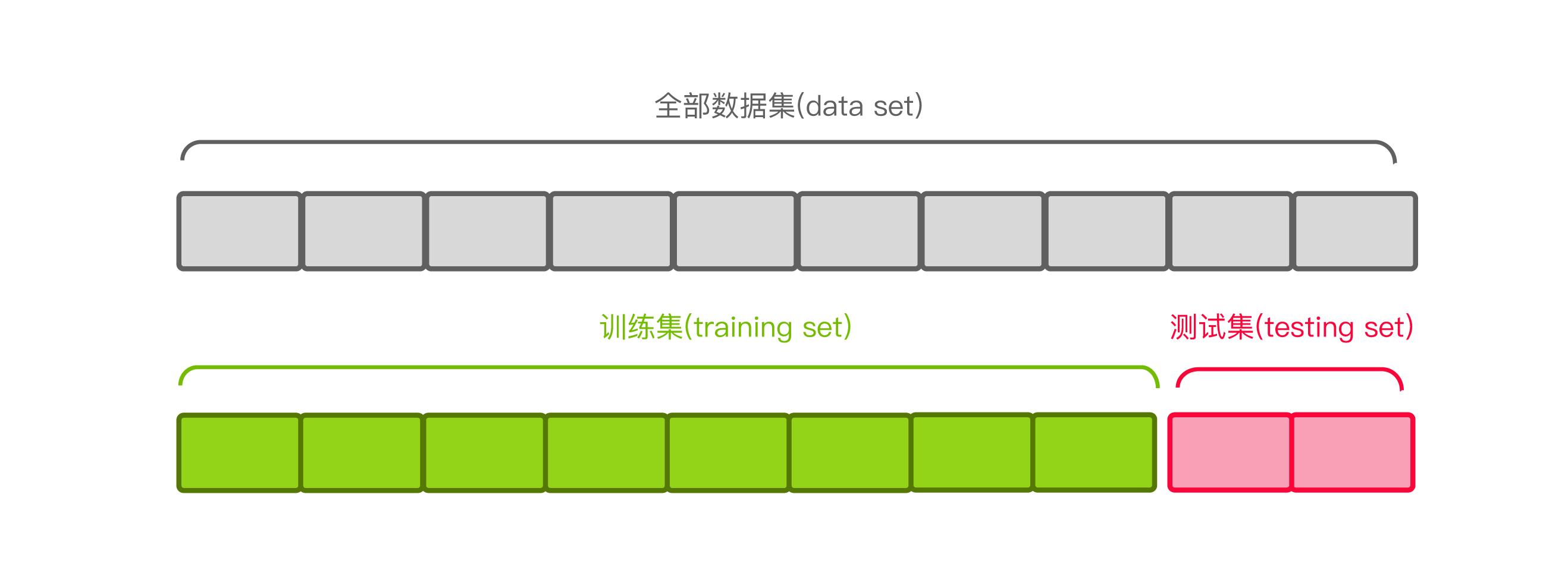
训练集用来训练我们的模型,它的作用就像我们平时做的练习题;测试集用来评估我们训练好的模型表现如何,它的作用像我们做的高考题,这是要绝对保密不能提前被模型看到的。
因此,在K折交叉验证中,我们用到的数据是训练集中的所有数据。我们将训练集的所有数据平均划分成K份(通常选择K=10),取第K份作为验证集,它的作用就像我们用来估计高考分数的模拟题,余下的K-1份作为交叉验证的训练集。
对于我们最开始选择的决策树的5个最大深度 ,以 max_depth=1 为例,我们先用第2-10份数据作为训练集训练模型,用第1份数据作为验证集对这次训练的模型进行评分,得到第一个分数;然后重新构建一个 max_depth=1 的决策树,用第1和3-10份数据作为训练集训练模型,用第2份数据作为验证集对这次训练的模型进行评分,得到第二个分数……以此类推,最后构建一个 max_depth=1 的决策树用第1-9份数据作为训练集训练模型,用第10份数据作为验证集对这次训练的模型进行评分,得到第十个分数。于是对于 max_depth=1 的决策树模型,我们训练了10次,验证了10次,得到了10个验证分数,然后计算这10个验证分数的平均分数,就是 max_depth=1 的决策树模型的最终验证分数。
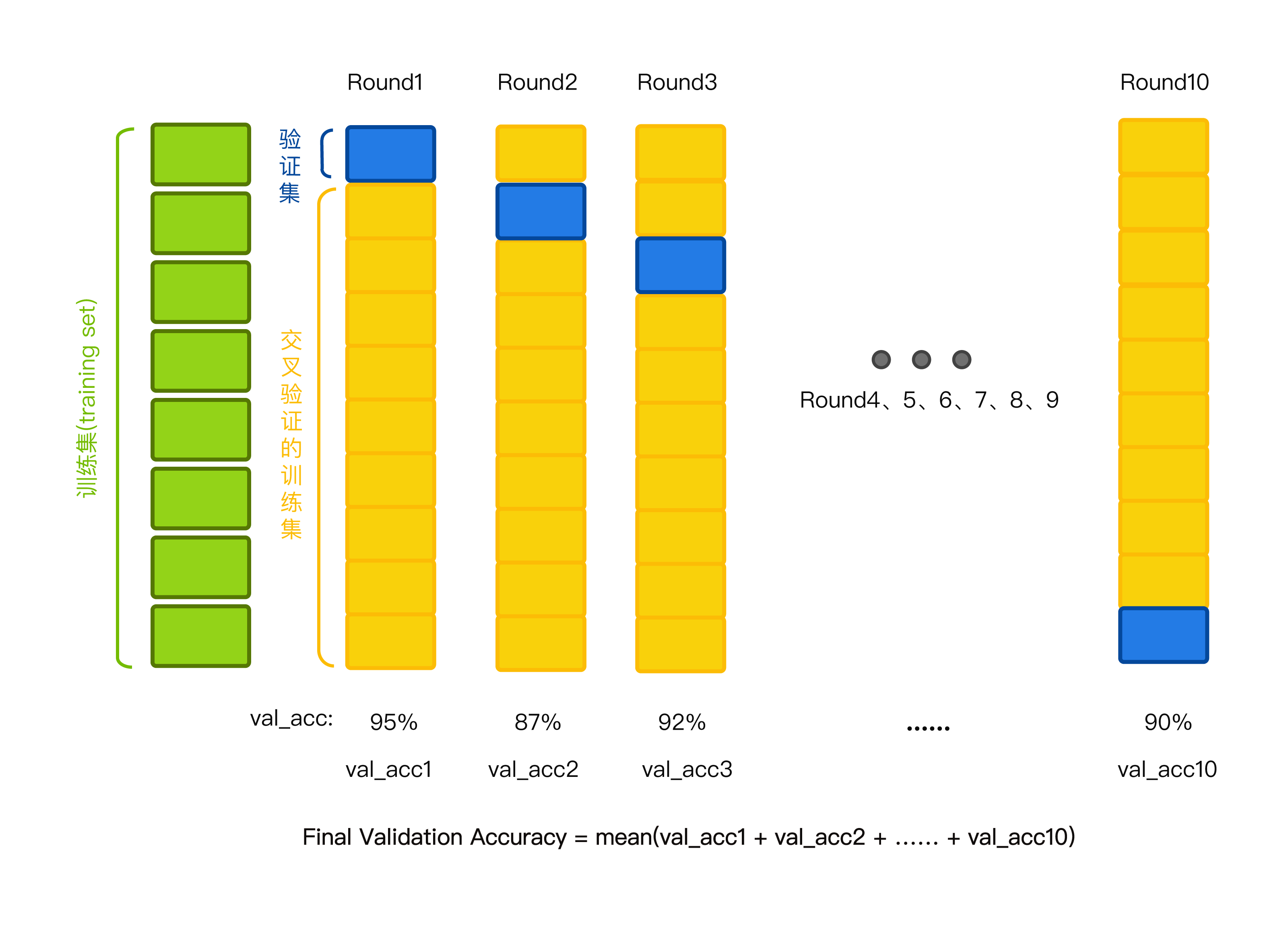
对于 max_depth = 2,3,4,5 时,分别进行和 max_depth=1 相同的交叉验证过程,得到它们的最终验证分数。然后我们就可以对这5个最大深度的决策树的最终验证分数进行比较,分数最高的那一个就是最优最大深度,对应的模型就是最优模型。
下面提供一个简单的利用决策树预测乳腺癌的例子:
1 | from sklearn.model_selection import GridSearchCV, KFold, train_test_split |
直接用决策树得到的分数大约是92%,经过网格搜索优化以后,我们可以在测试集得到95.6%的准确率:
1 | best score: 0.938462 |