from urllib import * from bs4 import BeautifulSoup
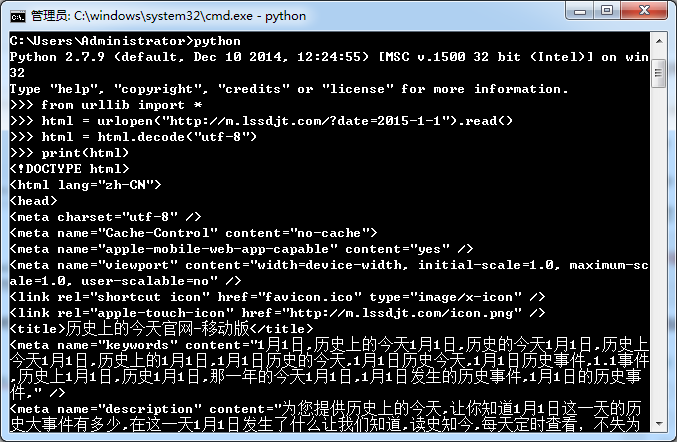
html = urlopen("http://m.lssdjt.com/?date=2015-1-1").read() soup = BeautifulSoup(html) for link in soup.find_all('a'): if link.string isnotNone: title = link.get_text() href = link['href'] print href, title
这里我们输出结果就十分漂亮了.
分析:
for link in soup.find_all('a'):
寻找所有a标签,也就是2010年-中国-东盟自贸区正式建成这样的标签,找到之后用link循环
from urllib import * from bs4 import BeautifulSoup
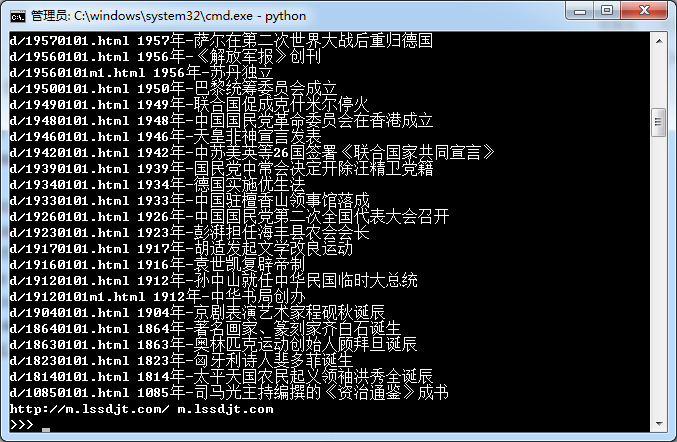
html = urlopen("http://m.lssdjt.com/?date=2015-1-1").read() soup = BeautifulSoup(html) f = open('data.csv', 'w') for link in soup.find_all('a'): if link.string isnotNone: title = link.get_text() print title title = title.encode("gbk") href = link['href'] urlretrieve("http://m.lssdjt.com/" + href, href) f.write(href + "," + title + "n")
f.close()
讲解:
f = open('data.csv', 'w') 以写文件('w')的模式打开data.csv文件
title = title.encode("gbk")
windows环境下,我们用gbk编码,excel才不会乱码
from urllib import * from bs4 import BeautifulSoup import socket
socket.setdefaulttimeout(3)
f = open('data.csv', 'w') r = "?date=2015-1-1" t = 0 whileTrue: t += 1 html = urlopen("http://m.lssdjt.com/"+r).read() soup = BeautifulSoup(html) r = soup.find("li", "r")['onclick'].split("'")[1] for link in soup.find_all('a'): if link.string isnotNone: title = link.get_text() print title title = title.encode("gbk", "ignore") href = link['href'] if href.find("html") > 0: success = True while success: try: print"getting " + href urlretrieve("http://m.lssdjt.com/" + href, href) success = False except IOError: print"超时"
f.write(href + "," + title + "n") print"这是第{0}天".format(t) if t > 365: break