部署 DeepSeek R1 32B + Open WebUI 教程
DeepSeek R1 厉害在哪
我觉得最主要的点在于,它具备思维的能力,是一个有智商的模型。
不同于 ChatGPT 的 gpt-3.5、gpt-4、gpt-4o 等模型,根据你的问题输出结果,即使说错了,也在错误的道路上狂奔。
R1 是能够思考,能够提出猜想,验证猜想,逐渐思考出正确答案的一个 LLM。这使得它的逻辑思维能力达到了一个新的高度。它的能力类似于 OpenAI 的 o1 模型,但是 o1 没有输出思维链,R1 会输出它的思维链,也就是思考的过程,所以我认为 R1 是目前开源的最强模型。
为什么要自己部署
一般来说,大家部署 LLM 都有这些目的:
- 探索,希望能够亲手试试最前沿的科技
- 折腾,希望挑战自己,探索没做过的事情
- 隐私,不希望自己的问答被发布到互联网上,成为 LLM 的燃料
- 商业,公司不希望任何核心代码发布到互联网上,担心商业泄密
- 稳定,目前 DeepSeek 的服务很不稳定,需要给自己留条后路
对我来说,每一点都是我的原因。
接下来让我们开始部署模型。
部署模型推理服务 Ollama
首先安装 Ollama
Windows、Linux、Mac 都支持,M 系列的芯片、英伟达系列的显卡的支持也都很到位,直接下载下来安装即可。
然后下载模型
参考链接:https://ollama.com/library/deepseek-r1:32b
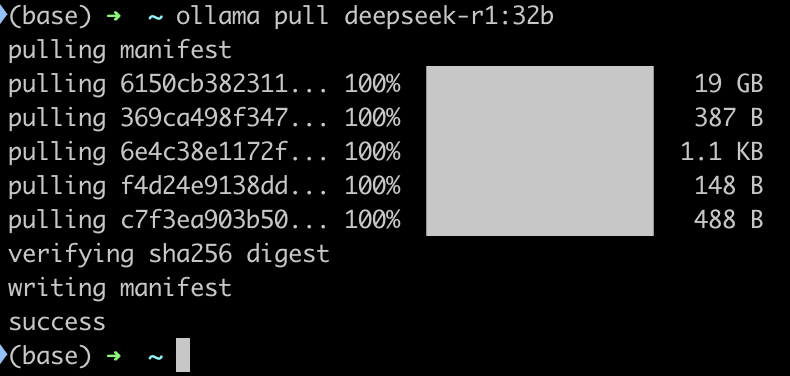
使用下面的命令下载模型:
1 | ollama pull deepseek-r1:32b |
显存超过 40GB,可以考虑 部署 70b 的模型,否则建议使用 32b 的模型。
显存多少 GB 就部署大概多少 b 的模型,比如 24GB 部署 32b,16GB 部署 14b,8GB 部署 7b。如果出现 OOM,也就是爆显存了,就部署小一档的模型。
如果有大佬想部署 671b 的原版模型,建议配置是八卡 H200,能达到 3872 token/s,显存是141GB * 8 = 1128GB。参考链接:https://blogs.nvidia.com/blog/deepseek-r1-nim-microservice/
验证模型
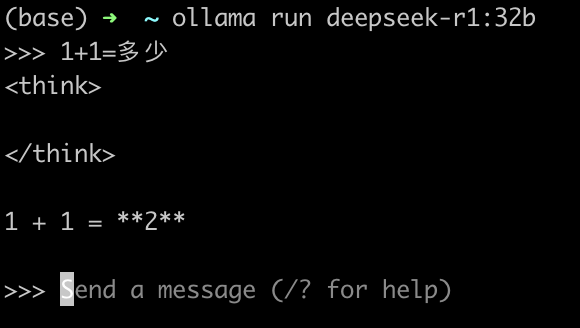
1 | ollama run deepseek-r1:32b |
输出 1+1=2 就说明模型下载好了。
部署前端服务 Open WebUI
建议使用 Docker 部署,不需要配置环境,避免环境冲突的影响。
若希望使用 Python 部署,参考官方文档:https://docs.openwebui.com/#manual-installation
安装 Docker
直接在官网下载:
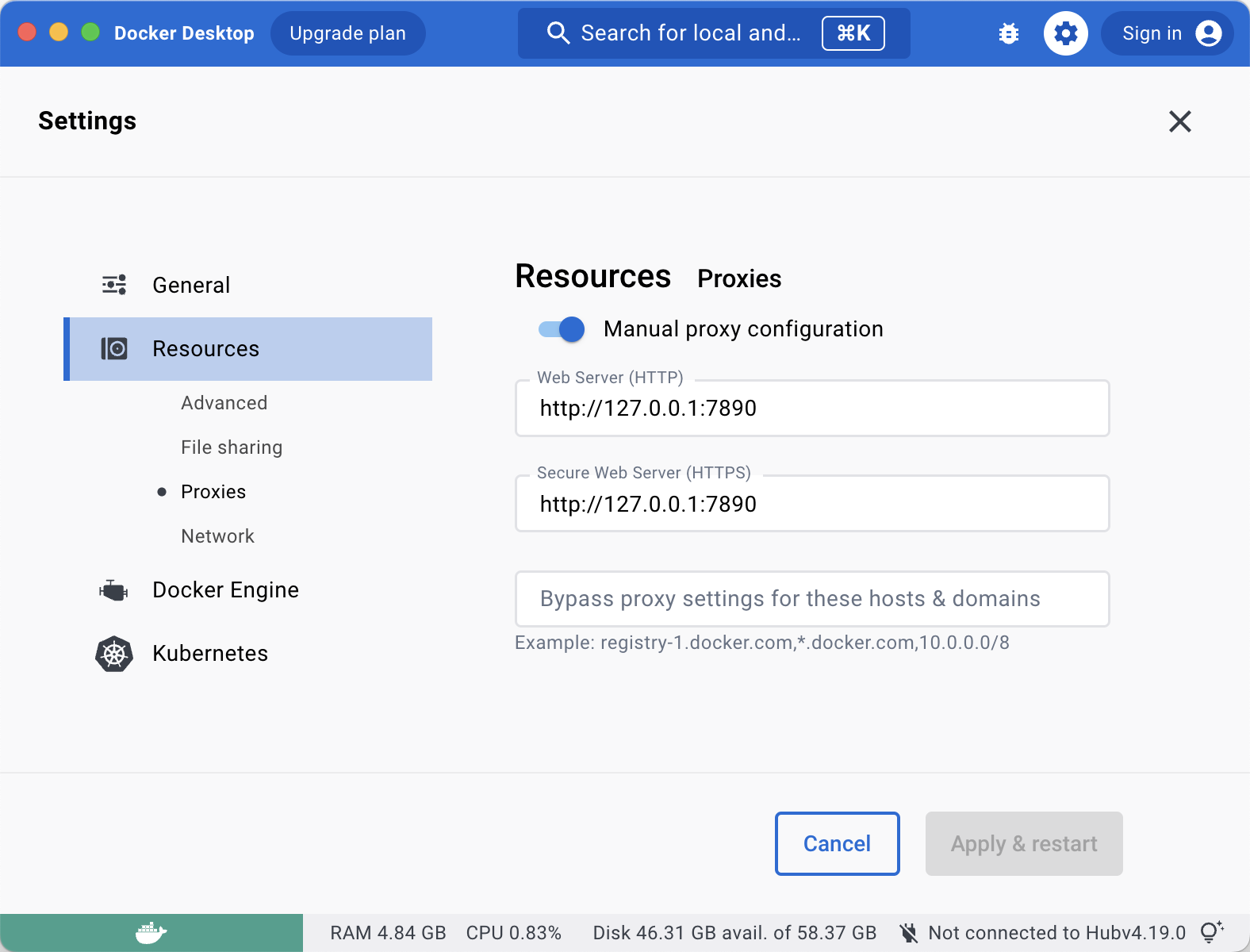
你可能需要配置
你可能需要配置这个:https://docs.docker.com/engine/cli/proxy/
使用 docker-compose 部署
首先将下面的文字保存为 docker-compose.yaml
1 | version: '3.8' |
在同级文件夹创建 data 目录,然后使用下面的命令启动:
1 | docker-compose up |
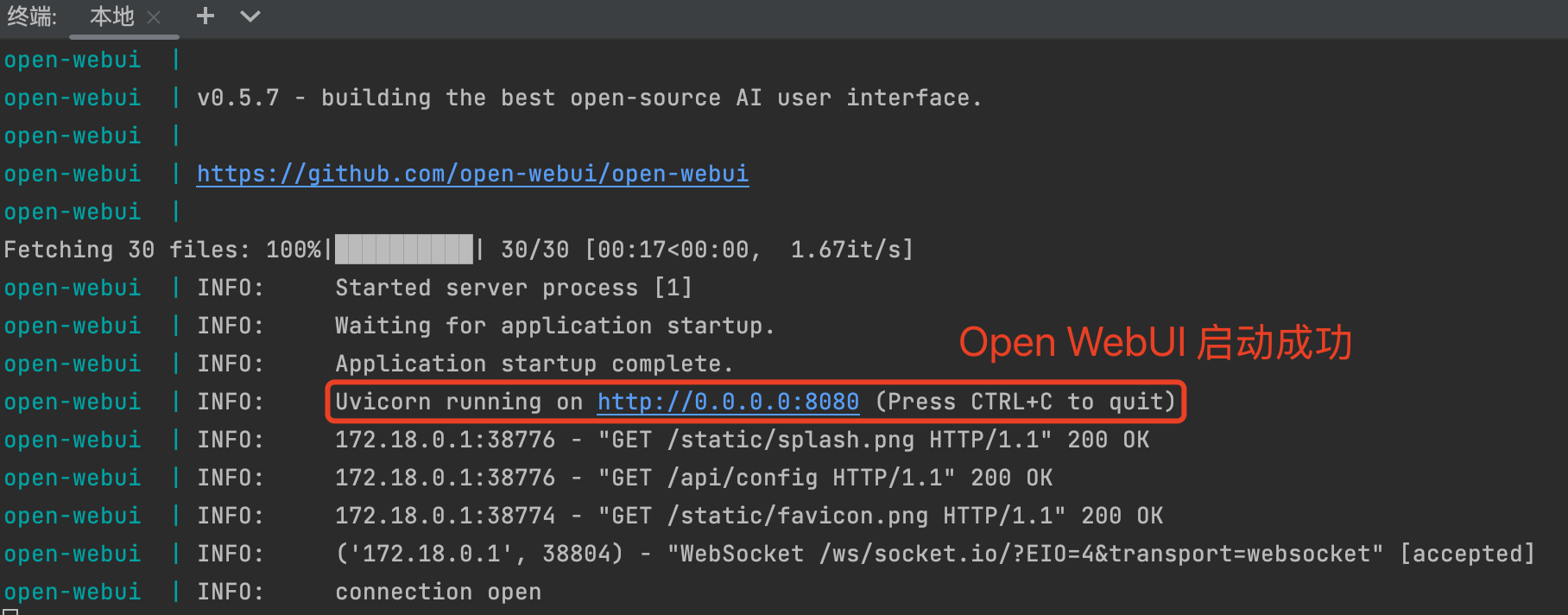
第一次启动需要较长时间,大概 2 分钟。启动成功之后是这样显示的:
其他常见命令:
1 | docker pull ghcr.io/open-webui/open-webui:main # 手动下载镜像 |
配置 Open WebUI
第一次启动可以看到这个提示:

根据提示创建管理员账号:

然后就可以开始使用了:
网络搜索
首先我们主要在管理员面板开启联网搜索,选择 duckduckgo 搜索引擎:http://localhost:3000/admin/settings
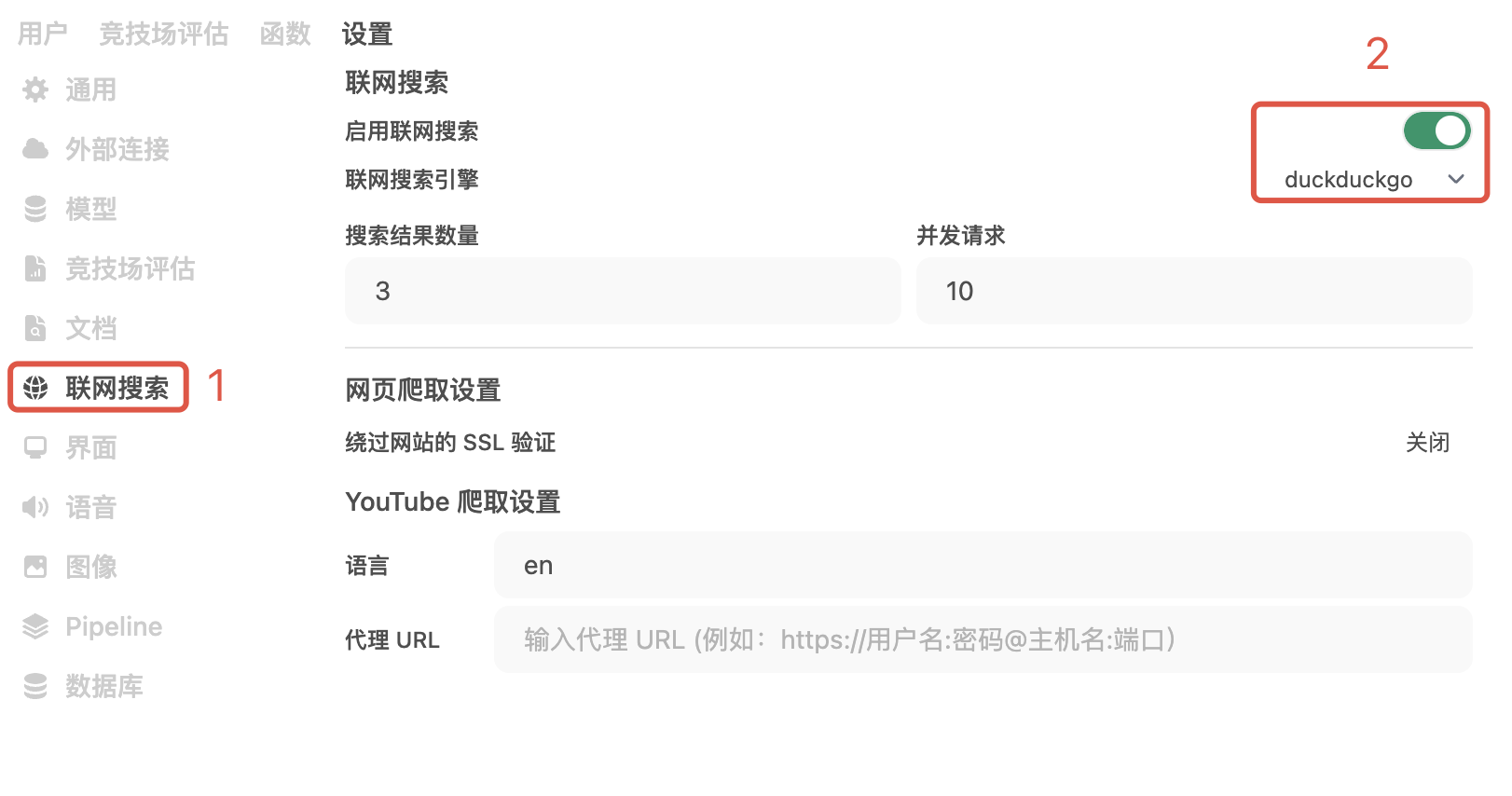
然后记得点保存。参考文档:https://docs.openwebui.com/tutorials/web_search
最后我们在聊天框中打开联网搜索的功能:
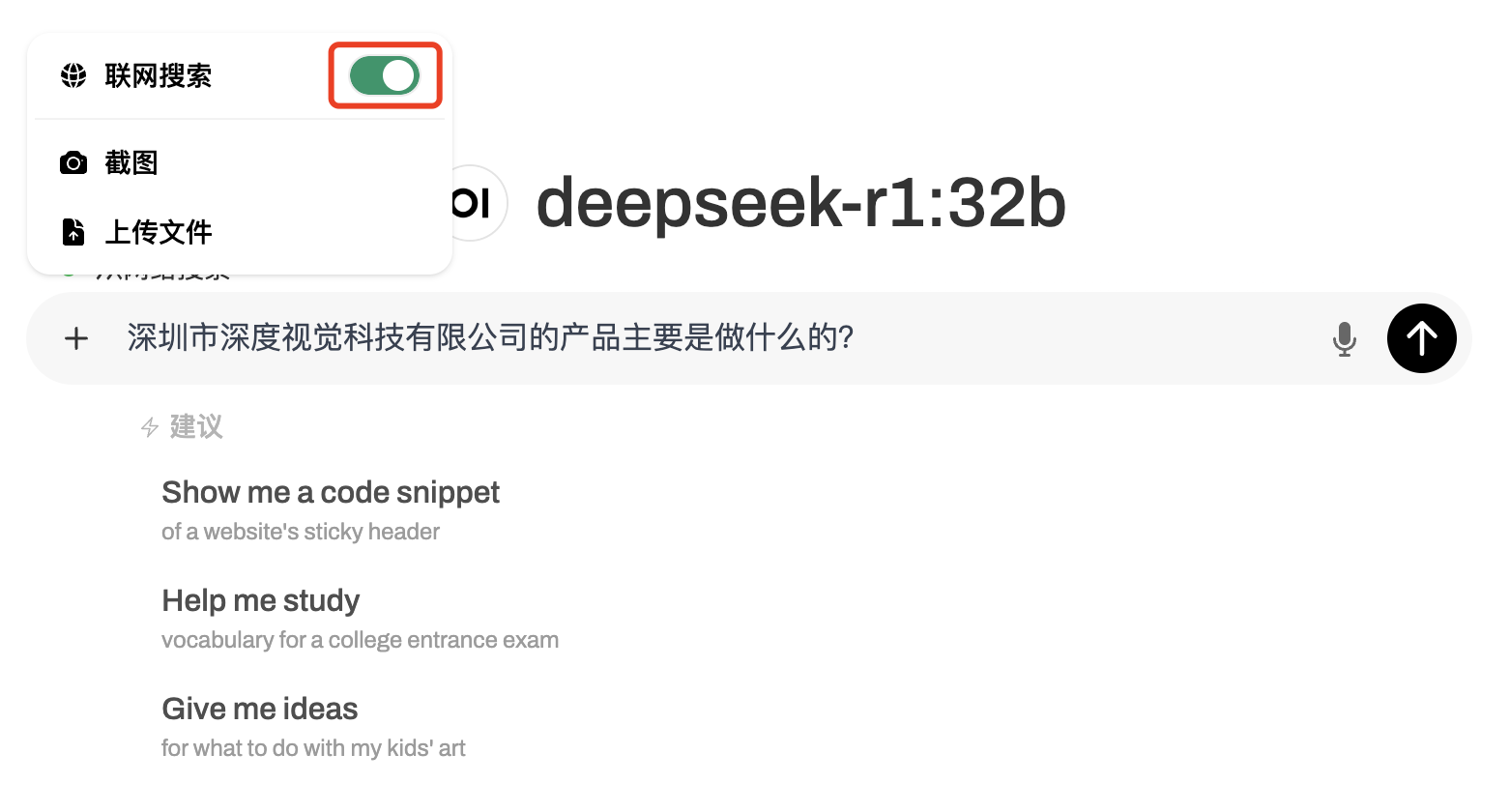
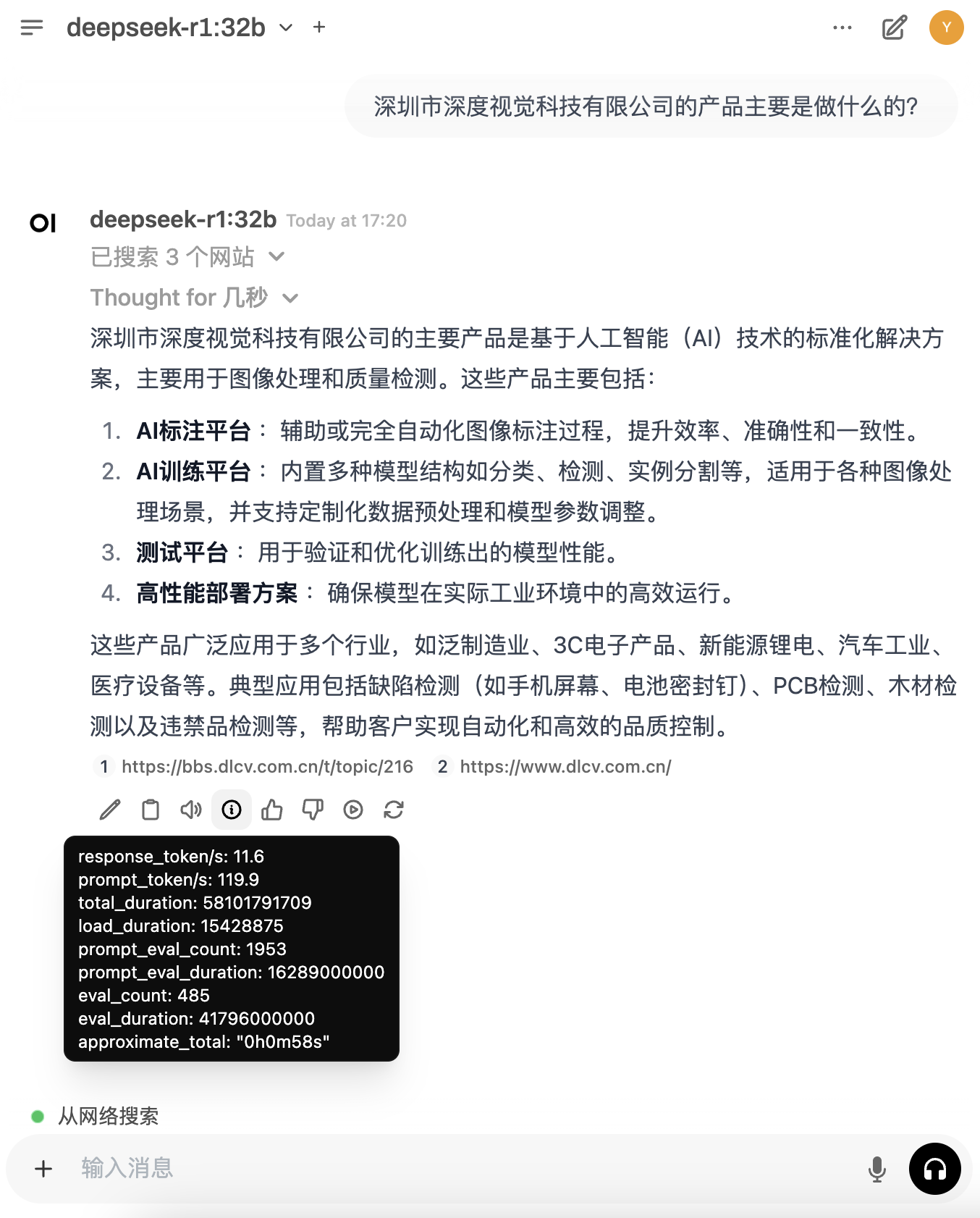
即可看到结合了搜索结果的回答:
性能分析
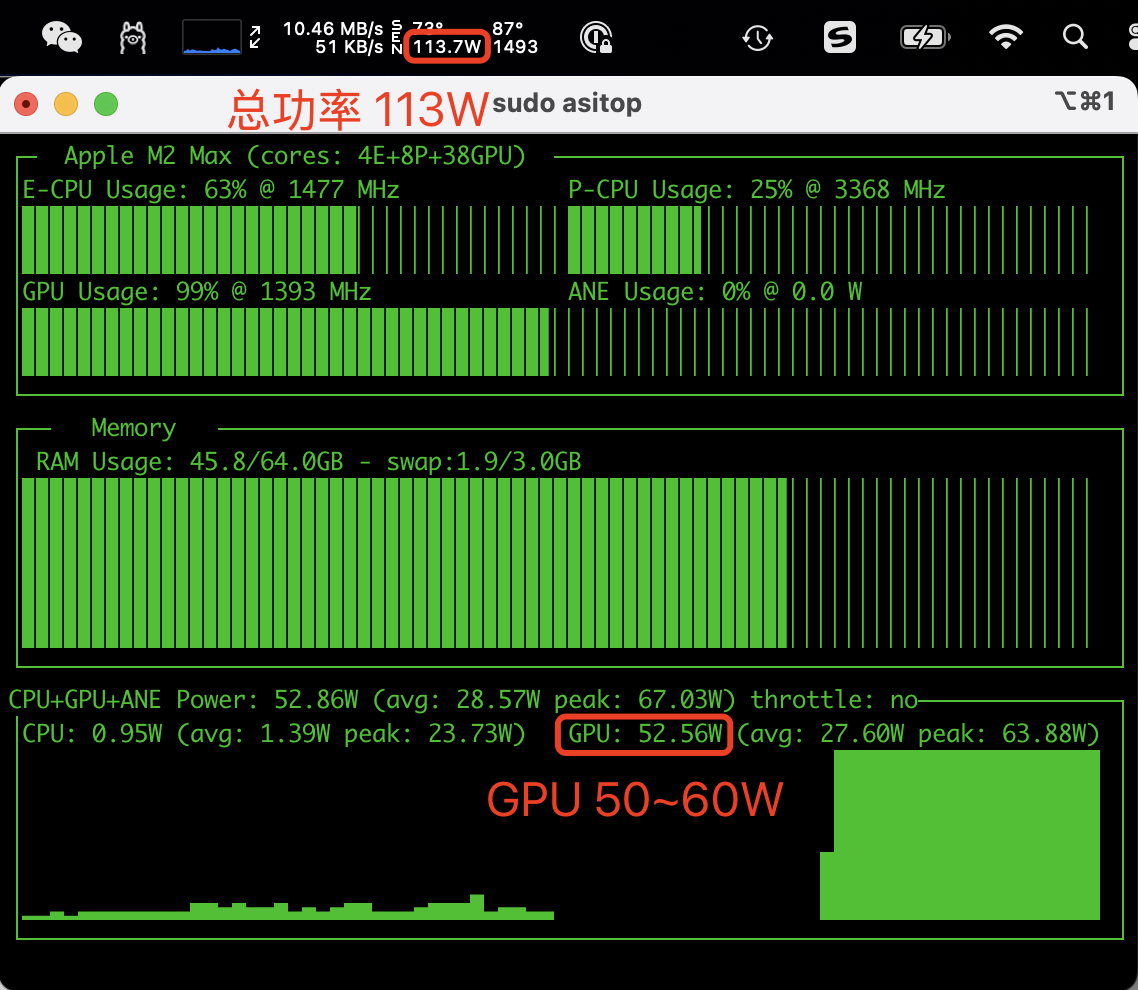
如果你用的是 Mac 推理,可以使用 asitop 和 iStat Menus 查看性能:
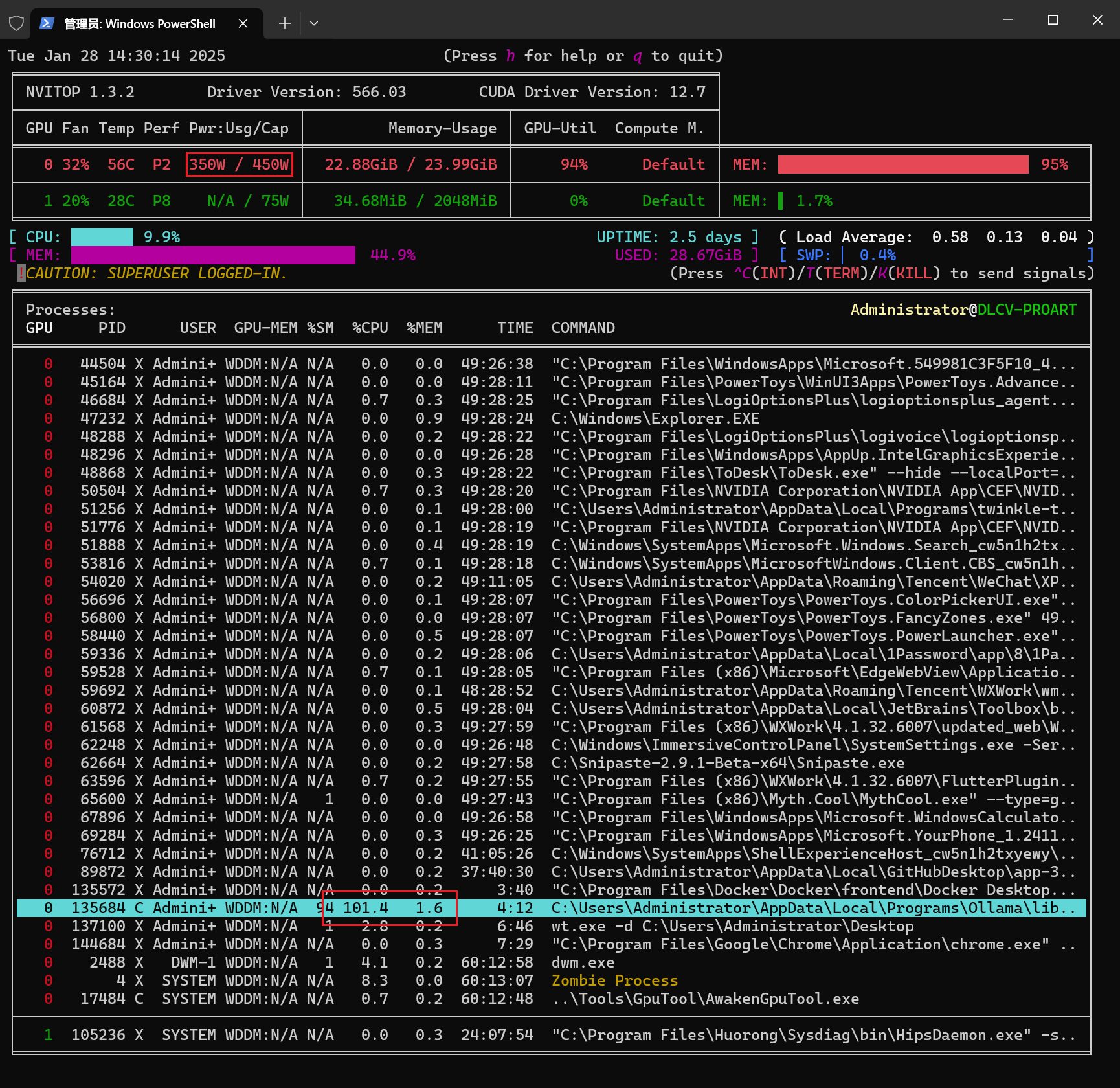
如果你使用的是 Windows 或者 Linux,用英伟达显卡推理,可以使用 nvitop 查看性能: